os-lab6
本文最后更新于 2024年9月6日 下午
思考题
6.1
以下是修改的代码:
1 | |
6.2
修改前的逻辑是:先对文件描述符(fd)进行映射引用,再对文件数据区(pipe)进行引用。这样会出现pageref(fd)比pageref(pipe)先进行更新的情况,也就是调用dup后pageref(fd)会比pageref(pipe)先加一。
如果子进程调用dup复制写端的文件描述符前,有pageref(p[1]) == pageref(pipe) - 1,而在dup中,如果p[1]已经被映射,而pipe还没被映射,此时转换到父进程运行,父进程调用pipe_is_closed(p[1]),判断此时的确满足pageref(p[1]) == pageref(pipe),就会错误得出管道已经关闭的错误情况了。
6.3
我们通过syscall指令触发异常,在陷入内核态处理系统调用时,已经通过对IEc置0来关闭所有中断了,也就是说,系统调用是通过“关中断”实现的原子操作。
6.4
- 可以解决。在任何情况下,必然存在不等式
page_ref(fd) <= page_ref(pipe),而当我们重新设置unmap操作的顺序的话,在两次unmap中间对pipe_close进行中断的话,使得fd的引用次数先减少,则必然有page_ref(fd) < page_ref(pipe)成立,因此不会在这个过程中对管道的开关过程发生误判。 - 会出现,见6.2
6.5
用户进程调用
user/lib/files.c文件中的open函数,其中又调用同文件夹下的fsipc_open函数,fsipc_open通过调用fsipc函数向服务进程进行进程间通信,并接收返回的消息。而相应的文件系统服务进程的serve_open函数调用file_open对文件进行打开操作,最终通过进程间通信实现与用户进程对文件描述符的共享。在Lab3中填写了
load_icode函数,实现了ELF可执行文件中读取数据并加载到内存空间,其中通过调用elf_load_seg函数来加载各个程序段。在Lab3 中我们要填写load_icode_mapper回调函数,在内核态下加载ELF数据到内存空间。
elf_load_seg函数:在该函数处理程序的循环中,当处理到.bss段时,该函数会调用map_page把相应的虚拟地址映射到物理页上,但不会从文件中加载数据。而在map_page的内部会调用load_icode_mapper函数将页面进行映射并根据参数将内容置为0;load_icode_mapper函数:当处理到.bss段时,不从源数据中复制任何内容。最终调用page_insert函数将其置入页表并指定权限。该函数会根据传入的参数在页表项中建立映射关系,并初始化页面为0.
6.6
1 | |
在shell初始化的过程中有上述代码,设置了文件描述符的0和1分别为标准输入和标准输出。
6.7
1 | |
参照上述代码,在MOS中我们用到的shell命令除了echocmds和注释两种情况外,都需要fork一个子shell来处理输入的命令。
Linux的cd指令使用频率较高,若设置为外部指令必然会在cd的时候多次调用fork生成子进程,这显然是低效的。将其设置为内部指令可以切实提高我们操作系统的效率。
6.8
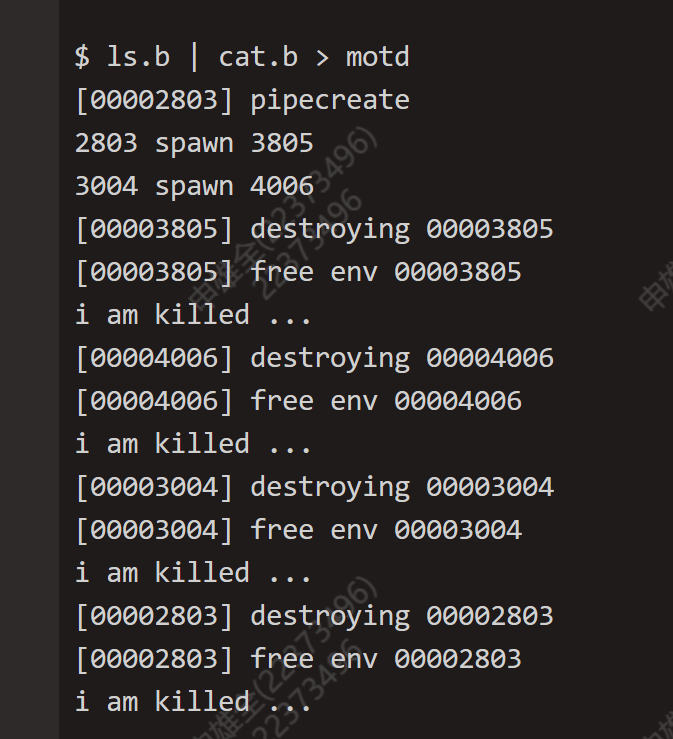
- 总共spawn了两次,分别是由最初被
fork出的2803进程spawn出了3805进程,以及3004(被2803进程在parsecmd时fork得到)进程spawn出了4006进程。 - 观察到了四次进程销毁:
2803进程:由主shell进程fork出来的子shell进程,用于解析并执行当前命令;
3004进程:由2803进程fork出来的子进程,用于解析并执行管道右端的命令;
3805进程:由2803进程spawn出来的子进程,用于执行管道左边的命令;
4006进程:由3004进程spawn出来的子进程,用于执行管道右边的命令;
实验难点
spawn函数
有点类似于fork函数的思路。
Step 1: 打开文件
1 | |
- 打开要执行的程序文件。
- 如果打开失败,返回错误代码。
Step 2: 读取 ELF 头
1 | |
- 从文件中读取 ELF 头部信息。
- 验证读取的数据是否正确且大小合适。
- 如果失败,设置错误代码并跳转到错误处理部分。
Step 3: 创建子进程
1 | |
- 使用
syscall_exofork系统调用创建一个子进程。 - 如果创建失败,设置错误代码并跳转到错误处理部分。
Step 4: 初始化子进程的栈
1 | |
- 使用
init_stack初始化子进程的栈。 - 如果初始化失败,设置错误代码并跳转到错误处理部分。
Step 5: 加载 ELF 段到子进程的内存中
1 | |
- 遍历 ELF 文件的程序头表,查找需要加载的段。
- 使用
read_map读取段内容到内存。 - 使用
elf_load_seg将段内容加载到子进程的内存中。 - 如果失败,设置错误代码并跳转到错误处理部分。
设置子进程的 Trapframe 和执行入口
1 | |
- 设置子进程的
Trapframe,包括程序计数器和栈指针。 - 如果设置失败,设置错误代码并跳转到错误处理部分。
共享页表条目
1 | |
- 共享页表条目中标记为
PTE_LIBRARY的页。 - 将这些页映射到子进程中。
设置子进程状态为可运行
1 | |
- 将子进程的状态设置为可运行。
- 如果失败,设置错误代码并跳转到错误处理部分。
错误处理部分
1 | |
- 如果任何步骤失败,销毁子进程并关闭文件描述符。
- 返回错误代码。
这个函数通过一系列系统调用和 ELF 解析过程创建并初始化一个新的子进程。主要步骤包括打开可执行文件、读取 ELF 头部信息、创建子进程、初始化栈、加载 ELF 段、设置 Trapframe 和共享页表条目,最后将子进程状态设置为可运行。整个过程包括详细的错误处理,以确保在任何步骤失败时都能正确清理资源并返回适当的错误代码。
parsecmd函数
解析函数逻辑
主循环:
- 使用
gettoken()函数获取下一个 token 的类型。 - 根据 token 的类型执行相应的操作。
- 使用
gettoken() 函数:
- 该函数返回当前 token 的类型,可以是
0(结束)、'w'(单词)、'<'(输入重定向)、'>'(输出重定向)、'|'(管道符号)。
- 该函数返回当前 token 的类型,可以是
处理逻辑:
case 0:结束条件,返回参数个数argc。case 'w':将单词t存储到argv数组中,并增加argc。case '<':处理输入重定向,打开文件t并复制到标准输入(0),处理错误情况。case '>':处理输出重定向,打开文件t并复制到标准输出(1),处理错误情况。case '|':处理管道,创建管道p,fork 子进程,子进程处理管道右侧,父进程处理管道左侧。
管道处理:
- 创建管道
p[2]。 - 调用
pipe(p)创建管道。 fork()函数创建子进程。- 子进程中,关闭不需要的管道端,并递归调用
parsecmd()处理管道右侧。 - 父进程中,关闭不需要的管道端,并返回当前命令的参数个数
argc。
- 创建管道
错误处理:
- 使用
debugf()输出错误消息。 - 使用
exit()终止进程。
- 使用
体会感想
比较轻松的一次lab,但是综合性也比较强,特别是后面两个函数比较复杂,涉及了之前的一些内容。
总之os告一段落了,自己对os有了整体的认识,但是具体到某个流程的分析,或许会有磕磕绊绊。收获很大。